Il down di Facebook ha svelato come Menlo Park vede le nostre foto
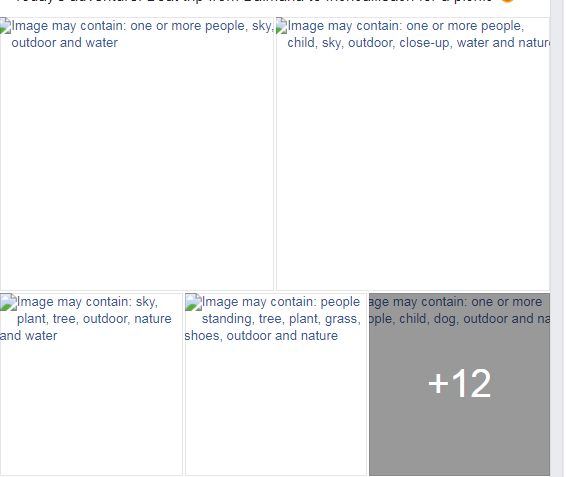

«La tua foto profilo: 1 persona, montagna, sorriso, tramonto». Il 3 luglio qualcosa nei server di Menlo Park ha smesso di funzionare. A partire dal primo pomeriggio Facebook, Instagram e Whatsapp hanno cominciato a dare problemi con le immagini, uno dei contenuti che circola di più su queste piattaforme. Al posto delle foto sono comparse, spesso, delle scritte.
Non solo. In molti non sono riusciti a condividere contenuti sui propri profili social e in alcuni casi non si riusciva nemmeno a inviarli via WhatsApp. Sembra che ora il bug sia stato risolto ma quello che resta di quella giornata di down è una traccia su come le piattaforme di Mark Zuckerberg archiviano le nostre immagini.
Mentre il sito non funzionava, invece delle fotografie dei nostri contatti si vedevano dei riquadri bianchi con delle descrizioni. La maggior parte iniziavano con la formula: «L’immagine può contenere». Per poi elencare cosa ci fosse in quell’immagine: mare, primo piano, fiore, abitazione. Una lista di tag insomma, delle parole chiave che identificano la foto, la categorizzano e la rendono più facile da riconoscere e da aggregare con altre foto simili.
Come sono stati creati i tag
James Vincent del giornale statunitense The Verge ha paragonato il momento in cui Facebook ha svelato i meccanismi dietro le sue foto con la scena della triologia di Matrix in cui Neo si rende conto che tutto quello attorno a lui è fatto di strisce di codice. In effetti è interessante vedere cosa sono quelle immagini per Facebook e Instagram.
I tag associati a ogni contenuto non sono stati caricati dagli utenti e nemmeno selezionati da qualche sfortunato dipendente costretto a catalogare a mano tutte le foto pubblicate sulla piattaforma. È tutto frutto di un lavoro più complesso, iniziato nell’aprile 2016.
È da qui che è partito un progetto di classificazione delle immagini che prevede l’utilizzo dell’intelligenza artificiale. Algoritmi sempre più allenati processano milioni di immagini e imparano a capire dalla posizione e dal colore dei pixel cosa rappresentano.
Quello che ancora non è chiaro è per cosa o come gli ingegneri di Menlo Park usino questa classificazione. Potrebbe essere solo per raccogliere più informazioni sugli utenti e capire quindi che tipo di contenuti vengono pubblicati su Facebook e Instagram. Oppure ancora potrebbe essere per questioni di marketing. Profilare meglio gli utenti permette di indirizzare con precisione chirurgica gli annunci, così da rendere la pubblicità ancora più efficace.
Come scoprire quali tag ci sono nelle nostre foto
Questa volta quindi, abbiamo visto chiaramente come ci vede Facebook. Per capire meglio questo meccanismo non serve però aspettare il prossimo bug. Su GitHub, social network dedicato agli sviluppatori, Adam “ageitgey” Geitgey ha pubblicato un’estensione per Google Chrome che permette di svelare questi tag. Il codice si può utilizzare anche per Firefox.
Leggi anche:
- FaceApp, come funziona (e come usa i dati) l’app che sta invecchiando tutti i vostri contatti
- Da Cambridge il primo robot-contadino: ha imparato a raccogliere la lattuga (o almeno ci prova)
- Trump frena su Libra: «Facebook diventi una banca a tutti gli effetti»
- Facebook, multa record per Cambridge Analytica: 5 miliardi di dollari per violazione della privacy, cosa rischia ancora Zuckerberg
- Facebook prova a recuperare sulla tutela della privacy: la nuova funzione per controllare i dati condivisi da app e siti
- Facebook e Instagram down in Europa, negli Stati Uniti e in Sud America
